Welcome back to our blog! On today’s schedule, we want to discuss some exciting topics in the NLP field. This time we are introducing you to AMR graphs and their unexplored potential in various NLP tasks, and how they can be incorporated in until now unsolved problems. There will be multiple articles that will explore the usage of AMR graphs in different problems and hopefully our research and work will contribute and get noticed by the community. With this article, we want to present our cross-lingual AMR pipeline that can avoid the problems of low-source languages when working with parsing AMR graphs and generating sentences from given AMR graphs.

Introduction
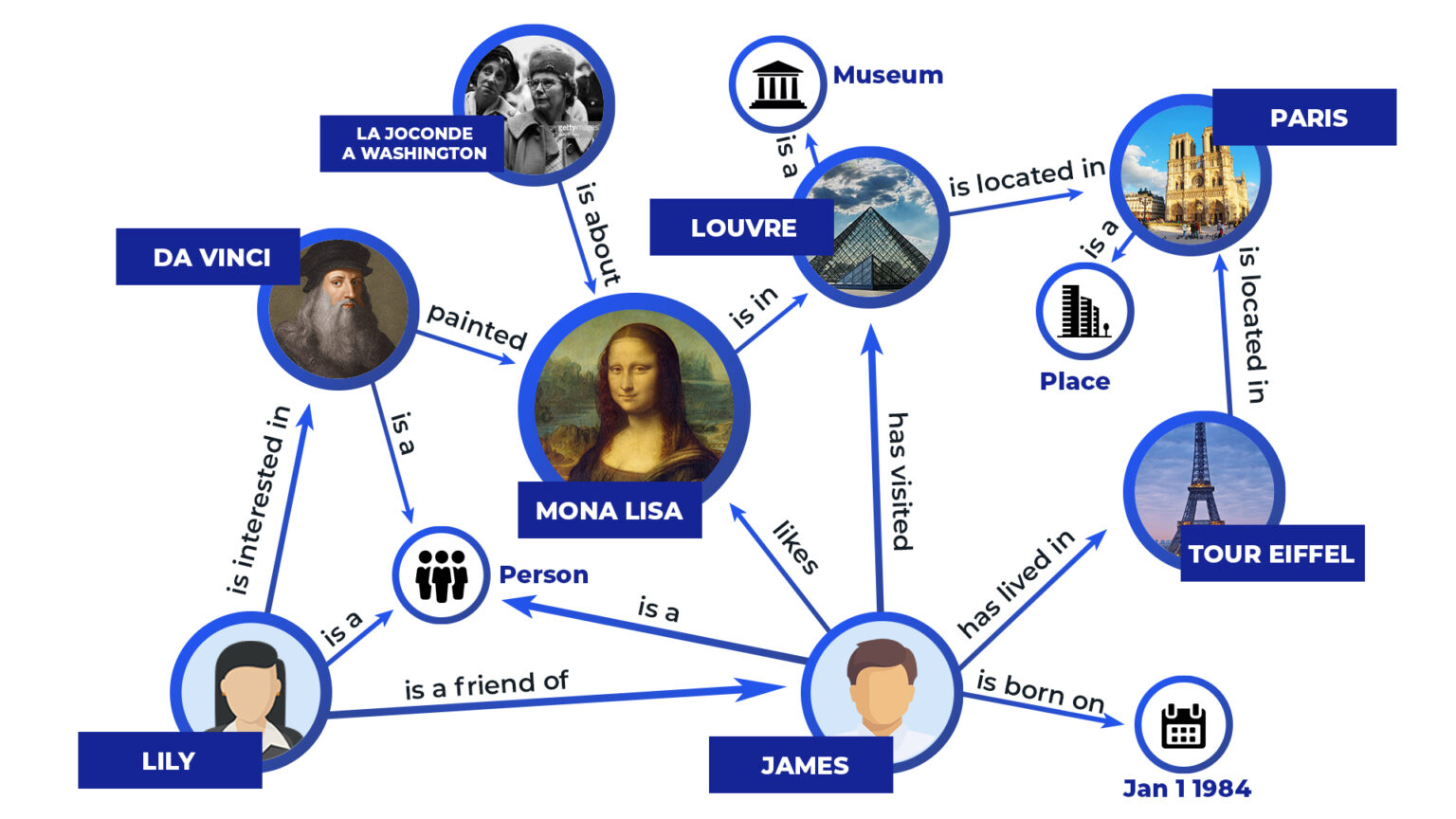
In this article, we introduce you to a cross-lingual AMR end-to-end pipeline. First, let’s briefly explain what AMR is. Abstract Meaning Representation (AMR) is a language for semantic representation that is introduced to the English language. The purpose of this representation is to present a sentence into an AMR graph. These graphs contain nodes that portray the entities in the sentence and edges which represent the existing semantic relationships between the nodes. The AMR graphs are described as rooted, directed, acyclic graphs with labeled edges and leaves. There are two main tasks when working with AMR graphs. The first one is called AMR parsing. Here, a given sentence is converted to an AMR graph, i.e., we parse each component of the sentence into its appropriate graph representation. The second task is called AMR-to-text generation and the goal is to obtain a sentence from a given AMR graph. These tasks require a lot of suitable data to train models on how to make these conversions.
Maybe you will ask yourself, why we need such complex representations. Let us explain it to you. There are many downstream NLP tasks that are doing some calculations but do not understand and preserve the semantic meaning of the input sentences. When using AMR graphs, the semantic meanings are preserved no matter what we are doing with the sentences, and many hidden meanings can be found when a sentence is observed as a graph. Some of the downstream tasks that implement AMR graphs are abstractive summarization, machine translation, paraphrasing sentences, etc.
These approaches can be introduced and contribute to improving and extending the coverage of semantic relationships in languages other than English. But there is one problem. In the first paper where AMR representations and graphs are introduced, it is stated that AMR is not intended to be interlingua, and only works for the English language. Because of this, there is a huge challenge when it comes to re-purposing AMR for other languages, i.e., making AMR cross-lingual stable.
Most of the existing models for AMR parsing and AMR-to-text generation in English work separately, they are either solving the parsing or the generating problem. Very few of them are incorporating both tasks into one framework, but recent researchers are succeeding in combining these tasks.
The next big challenge is to build multilingual AMR parsers and generators. Same as the models for English, there is little research on creating end-to-end AMR systems. Many of the existing systems are solving either the parsing or the generating task. Another important challenge in creating such systems is the small amount of cross-lingual data. The existing AMR parsers and generators usually use manually annotated AMR graphs so they can train and evaluate the models, but that kind of work requires creating a lot of data and human resources.
We propose a novel strategy for developing end-to-end cross-lingual AMR systems, motivated by the aforementioned challenges. In the next chapter, we will describe how we incorporate the benefits of state-of-the-art translators in these kinds of problems.
Methodology
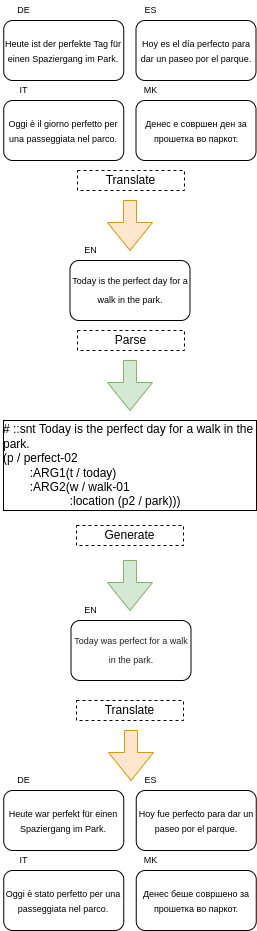
The methodology that we are proposing consists of a pretrained translator and a state-of-the-art English-based AMR model. Shortly explained, for a given non-English sentence first, we translate it into an English sentence, and we handed it over to an AMR parser which outputs AMR graphs. This AMR graph is then run through an AMR generator which results in an English sentence as an output. In the final step, the generated English sentence is translated to the original source language. We named this pipeline xAMR and it represents a full end-to-end cross-lingual AMR parsing and generating pipeline.
Our pipeline consists of four key steps, and it is shown in Figure 1:
- Forward Translation – Translating non-English sentences into English using two translators (TxtAi and DeepTranslator’s Google Translator)
- AMR Parsing – Parsing the translated English sentence into an AMR graph using Amrlib’s T5-based parser that has been fine-tuned on English sentences
- Text Generation – Generating English sentence from the AMR graph created in the previous step
- Backward Translation – Translating the English sentence into its source language
Dataset
We are using the Europarl Corpus which is a parallel corpus constructed for statistical machine translation and consists only of the languages that are spoken in the European Parliament. For the purposes of our research, we are using the German, Italian, Spanish and Bulgarian dataset. We chose these languages because we were able to find suitable multilingual AMR representations to compare our findings to. Additionally, we manually translated a subset of the English Europarl corpus into Macedonian since this language is not spoken in the European Parliament. This change was introduced as an example of how low-resource languages will act in such representations and models.
Evaluation metrics
As the main evaluation metric, we use cosine similarity on the sentence embeddings. Each input sentence is compared with the output sentence generated between each phase. With the help of the sentence embeddings and the cosine similarity, we can see how much one sentence is similar to another when comparing their textual structure which encompasses their semantic meaning and relationships. Because we are working with non-English sentences, we employ multilingual sentence embeddings such as LASER, LaBSE, and Distiluse-Base-Multilingual-Cased-v2.
Moreover, we measure BLEU and ROUGE scores between the input sentences and the output sentences in their source language. These metrics are standard practice when it comes to comparing sentences in terms of overlapping words. BLEU measures the matches in n-grams in the generated sentence that appeared in the input sentence, and ROUGE calculates how many of the overlapping n-grams in the input sentence appeared in the generated output.
Experiments & Results
The cosine similarity score determined between the various intermediate stages of the input text when sent through the xAMR pipeline is shown in Table 1. The input sentence in the selected language is denoted by X, the translated sentence is denoted by EN, and the parsing and generating task is denoted by AMR. We compare the two intermediate outputs when the notation is in capital letters.
Each column of the tables represents the cosine similarity computed between the original non-English sentence compared with its translated English version, the English sentence after its AMR generation, and the final output of the pipeline, respectively. The cosine similarity is calculated over the different sentence embeddings.
For the translation processes in the pipeline, two different translators had to be considered due to the inconsistencies in the Bulgarian language translation. The translators of interest are Txtai and Deep- Translator’s GoogleTranslator (only for translating Bulgarian sentences into English).
Table 1: Cosine similarity comparison between the original non-English input and the intermediate outputs of the pipeline.

With LASER embeddings we obtain the highest scores compared to the other two. Moreover, from the last column, we see that the original input sentence and the final output of our pipeline have leading scores, hence we can conclude that the pipeline truly keeps the semantic meaning of the sentences. In terms of the languages, the Spanish dataset obtained the best scores regardless of the sentence embeddings.
Table 2: Results for BLEU.
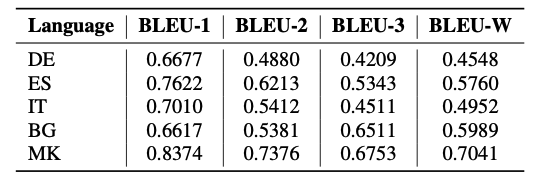
Table 3: Results for ROUGE.
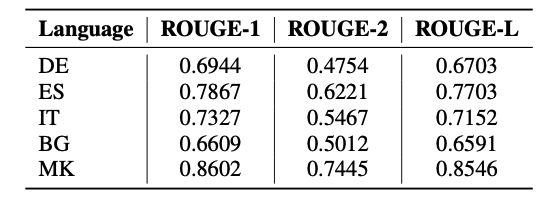
Additionally, the non-English sentences, the inputs in our pipeline, and their respective outputs are further compared using the BLEU and ROUGE – F1 metrics. In Table 2 and Table 3 we present the BLEU and ROUGE scores respectively. For each pair, we measure overlapping unigrams, and bigrams with both BLEU and ROUGE, as well as some auxiliary measures such as overlapping trigrams, longest overlapping sequence, and a weighted score of overlapping n-grams.
In comparison with the cosine similarity, BLEU and ROUGE obtain lower results because of the paraphrasing that happens during the generation from AMR and the translation processes. Nevertheless, these metrics provide an overview of the similarity of the syntax and the word order of the input and output sentences.
Once again, the Spanish dataset has the highest BLEU and ROUGE scores.
In order to gain more knowledge on how good our results are, we compare our pipeline with an existing multilingual AMR-to-text generator model, (mAMR) (Fan and Gardent, 2020). Since the mAMR model has already been evaluated on a subset of parallel sentences from the Europarl dataset, we evaluated our model too on the same dataset to gain more perspective on the results. We took 1000 pairs of sentences and AMR representations in German, Spanish, Italian, and Bulgarian and evaluated both of the models, our xAMR pipeline and the mAMR model on the same set. The Macedonian dataset is not evaluated with mAMR since it is not supported by the model.
In this manner, we obtain four datasets containing original English sentences, their respective simplified AMR graph, and the parallel sentence in the chosen language that serves as a reference.
The Macedonian language dataset is solely used to test the xAMR pipeline; nevertheless, because Bulgarian is the most comparable language to Macedonian, the success of an mAMR trained on Macedonian may be assumed from the Bulgarian mAMR.
To compare our pipeline to mAMR, we begin our pipeline from the parsing stage. As input in both models, we have the original English sentence. In xAMR that sentence is first parsed into an AMR graph. Next, the AMR graph generates another English sentence, which, lastly, is translated to the selected language. In mAMR, the input sentence is run through their model, and it generates a sentence in the chosen language. With the help of cosine similarity, we measure the semantic meaning between the input English sentence (EN) and the reference sentence in the source language (OrgX), and the generated outputs from both models (GenX). Finally, the outputs of both models (xAMR and mAMR) are compared to the reference sentence in the selected language to understand the significance of the results. The results are shown in Table 4, the cosine similarity was measured on the three different embeddings.
Table 4: Cosine similarity comparison on xAMR and mAMR.
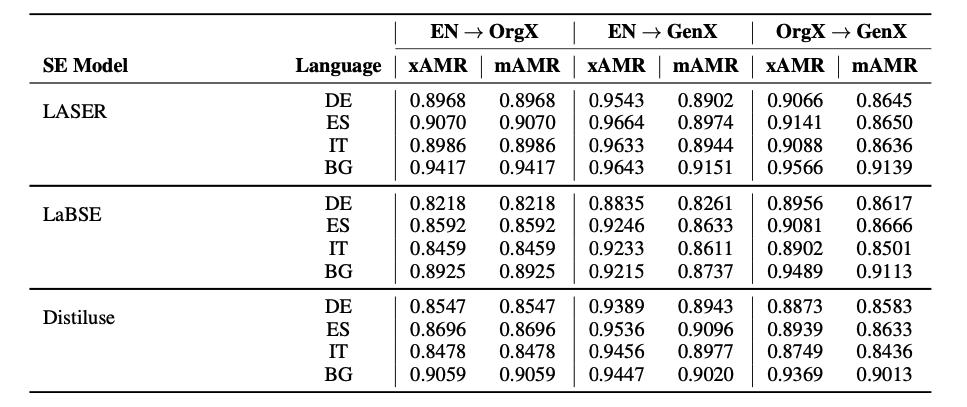
Again, the best results are acquired when LASER is used for sentence embeddings. It can be noticed that our method produces sentences that are more similar to the original reference sentence, unlike mAMR. Also, it can be noticed that our pipeline generates sentences with less information loss from the column EN -> GenX. Regardless of the applied sentence embedding, xAMR shows constant improvement in the range of 0.03 to 0.04 through all languages.
Tables 5 and 6 present the results acquired with BLEU and ROUGE when the reference non-English sentence is compared with the generated outputs from our xAMR and the mAMR model. Once more, xAMR surpasses the mAMR model most of the time.
Table 5: BLEU scores comparison on mAMR and xAMR.

Table 6: ROUGE-F1 score comparison on mAMR and xAMR.
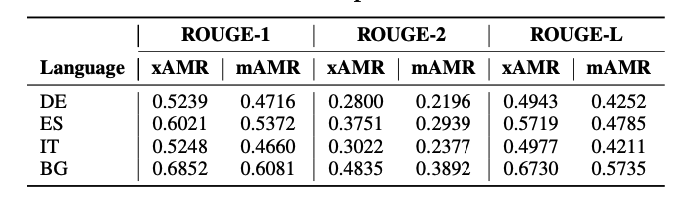
As a final review, we are comparing the generated outputs from both models with each metric that we have mentioned, just to observe how similar sentences both of the strategies produce. The results are in Table 7, and it can be concluded that both methods provide sentences with similar meaning but have distinct sentence organization observed from the BLEU and ROUGE metrics.

With that, we can confirm that our method successfully outperforms the previous method for multilingual AMR-to-text generation without the need for pre-training models on large, annotated data.
Conclusion
This article presents the findings of our paper. With this novel approach, the xAMR pipeline, we succeeded in creating a cross-lingual end-to-end system for AMR parsing and generation without the need for large multilingual corpora. We made a few impactful contributions: we used a benchmark dataset, so our pipeline can be compared with the existing multilingual AMR parsers and generators, we use standard evaluation metrics such as BLEU and ROUGE, but we also incorporate the cosine similarity metric to measure the actual semantic similarity between the sentences, and finally, we introduced one low-resource language – the Macedonian language and showed that xAMR can be used in any language. The experiments proved that xAMR significantly surpasses multilingual AMR models for all of the applied languages.
If you are interested in the xAMR pipeline, please check this link.




{kind=link}