
Macedonian and Croatian Language Implementation
Welcome back! As promised, we are continuing with our articles where we describe the submodules that comprise our OpenBrain framework. Today, we will focus on one of the most essential modules: the Speech-to-Text engine. This engine is based on deep learning techniques and is built upon hundreds of hours of speech transcribed into a textual form. This article will concentrate on developing such a system for low resource languages, like the Macedonian and the Croatian languages.
Introduction
What is the purpose of Speech-to-Text systems? Speech-to-Text systems are transforming a speech into a textual form and recent achievements in terms of architecture have reached state-of-the-art results. As the amount of available spoken data is growing, it opens space for developing improved models. These systems can be considered as part of the assistive technologies as they are incorporated in many systems which interact with the users. Such systems are the voice assistants which can understand speakers’ intentions through their conversion of the human speech to text and respond accordingly. Through this definition, you can notice why these engines are of great importance to our OpenBrain framework. Furthermore, the combination of speech-to-text and text-to-speech engines can be used by people with disabilities when they have trouble engaging on the internet so these technologies can help them execute simple requests.
Besides the recent state-of-the-art results, speech-to-text systems still encounter two great challenges. Those are the amount and availability of data, and the computation resources for training such models. When speaking of the first problem: the lack of data, depending on the chosen strategies and technologies, two types of architectures are possible, supervised and unsupervised. The supervised architectures and strategies require hundreds of hours of clean speech and corresponding transcribed data which additionally demand manual input. In contrast, the unsupervised approach does not require as much human effort to label the data.
Moreover, not only the amount of data is challenging, but also the variety of the data. For a highly achieving system, diversity of data is needed in terms of different voice characteristics, dialects, speakers, and various environments.
These difficulties exist for every speech-to-text system, but they increase when it comes to developing models for low-resource languages, such as the Slavic languages, more precisely, the Macedonian, and the Croatian language. There are many attempts to create speech-to-text models for Slavic languages but most of them rely on N-gram language models which have their own challenges and insufficiencies. With the development of deep learning techniques, we are implementing a speech-to-text system based on the Wav2Vec architecture. Our implementation forms an end-to-end system where the input features are directly mapped into output words.
Methodology
We are using the pretrained model Wav2Vec2 also known as XLSR. This model is pretrained on 53 languages, where Macedonian and Croatian languages cannot be found. So, we are fine-tuning the model on a custom-made dataset.
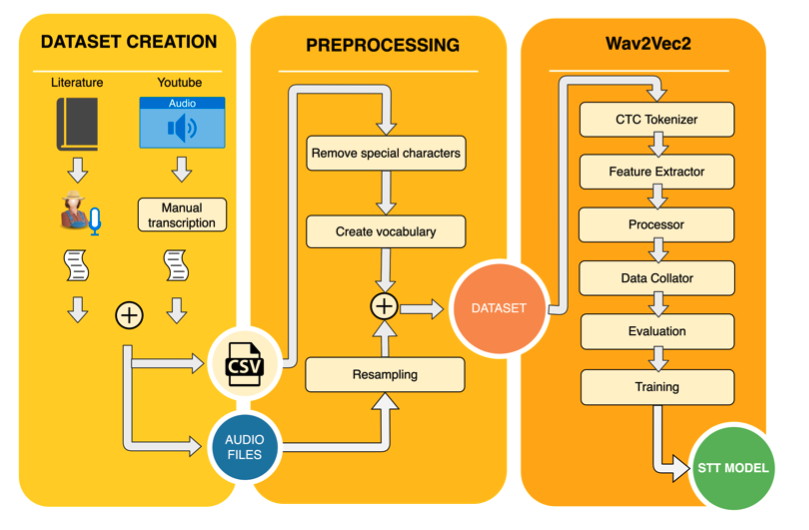
Figure 1: The architecture used for training Speech-to-Text models in Macedonian and Croatian languages.
In figure 1 we present our methodology. The following sections will briefly describe each of the phases.
Dataset
For the purposes of our work, we collected two datasets, one in Macedonian, and the other one in the Croatian language.
Macedonian dataset
The Macedonian dataset was collected in two environments, one controlled and the other was noised setup. The controlled environment serves to obtain clean and smooth voice recordings where each of the words will be heard loud and clear. The first dataset that we used was conducted during our research in text-to-speech systems, where we developed MAKEDONKA, the first Macedonia text-to-speech synthesizer. In this dataset, we have voice recordings from a female speaker and corresponding textual sentences. To increase the size of the dataset, additional voice recordings were collected from two male, and two female speakers with different dialects from distinct regions of Macedonia. The noised environment is made up of publicly available YouTube audio files of TV shows, news, interviews, etc. All of these files were manually transcribed, and, in that way, we produced around 95 hours of speech in the Macedonian language.
Croatian dataset
For the Croatian dataset, we used the Croatian text-to-speech to produce artificial data from a single female speaker. Same as the Macedonian dataset, additionally YouTube audio files were crawled and manually transcribed, and we produced 45 hours of speech in the Croatian language.
Preprocessing of the datasets
The preprocessing is done in two steps:
- Preprocessing of the text data – removing special characters, and only remaining characters are from the Macedonian Cyrillic alphabet and the Croatian Latin alphabet accordingly.
- Preprocessing of the audio data – resampling the audio files to a sampling rate of 16 kHz.
Furthermore, from the clean transcribed text dataset we create two vocabularies for both languages. Because the Croatian dataset is smaller, we transcribed Macedonian transcription in the Croatian alphabet, as both languages have the concept “read as you write”. In this manner, we created two datasets that contain 95 hours in the Macedonian language and 132 hours when both languages are combined.
Architecture
As aforementioned, we fine-tune the Wav2Vec2 model on our dataset. To the pretrained checkpoint, we add a linear layer at the top of the transformer network with an output size equal to the number of tokens in the vocabulary files that we created, 33 tokens for the Macedonian language and 30 tokens for the Croatian language. The preprocessed vocabulary files were used as input to the Wav2Vec2 CTC Tokenizer used for mapping the context representations to tokens. Next, the Wav2Vec2 Feature Extractor use raw speech as input with a sampling rate of 16KHz, and all the sequences were segmented for a duration of approximately 10 seconds. The tokenizer and the feature extractor were wrapped into a single processor for further usage.
Evaluation
These kinds of architecture evaluate the performances of the models using the word error rate (WER) metric which basically measures the number of errors divided by the total number of words.
We are still experimenting we different hyperparameters and settings to train the best high-achieving models. But, from the initial experiments, we have promising results for both models, where we obtain 0.2528 WER for the Macedonian language and 0.2561 for the Croatian language. Once again, our models are still under development, so keep following us for the final revelation of our findings.
Conclusion
Although there is a lot of research in this field, there are still great issues that need to be addressed when it comes to building speech-to-text models for low-resource languages. Moreover, the structural and morphological characteristics of the Slavic languages (in this case Macedonian and Croatian) make the development of these engines even harder and more challenging when it comes to available data and training the models for the features of those languages. However, the existence of these models is of great importance. Speech-to-text engines can be incorporated into every system that needs transcription of the data, such as any type of call center, smartphones, smart cars, smart homes, etc. Encouraged by these demands, we thrive to build a model that can be easily integrated into different systems, can be easily re-purposed for different Slavic languages, and can be a great tool in our OpenBrain framework.
Thank you for your attention.
Remain alert for more updates on our research!




{kind=link}
Zdravo
Naletio sam na članak preko LinkedIna pa sam htio konkretno pitati za navedene jezike, makedonski i hrvatski. Odakle vam to, kako obrađujete podatke i tko vaše podatke obrađuje ručno? Ipak, radi se o velikoj količini podataka. Zanima me tvrtka, mislim da ima potencijala.
Pozdrav, sve najbolje