

Next on the list is the Typo-Correction model. This type of model is used in the Application Layer of our OpenBrain framework along with the other intelligent models to create a more human-like communication experience. The following article is dedicated to its architecture and implementation, and it is the first part of a two-part article. Today we will describe the usage of state-of-the-art models and how we re-purposed them for the Croatian language. In the next article, we will focus on the Macedonian Typo Correction Model, so stay tuned to see how we managed to build typo correction models for two low-source languages.
Introduction
Spelling correction systems, also known as typo correction systems, play an important role when applied in complex NLP-based applications and pipelines. We created an intelligent typo correction model which works in pair with the speech-to-text engines with the aim to correct the misspelled words. When the output of a speech-to-text engine is generated, it is first run through this spelling correction model and then presented to the end-user. Because an instance of the OpenBrain framework can be instantiated in any language that has enough resources to train its required components, we are in the process of creating an instance in the Croatian language, similar to the structure of MAIA. For those purposes, we need a model which can accurately correct the misspelled words generated during the transformation from speech to text.
There are many existing models and techniques that are developed to support the English language as one of the languages with the most available resources for training. But only a few of them provide the opportunity to adapt to other, low-resource languages like the Croatian and Macedonian languages.
In this article, we are summarizing our experiments and results that we have published in the paper: NLP-based Typo Correction Model for Croatian Language. In the paper, we explore the power of the state-of-the-art Neuspell Toolkit for training an original spelling correction model for the Croatian language. We are comparing three different pre-trained Subword BERT architectures, BERT Multilingual, DistilBERT, and XLM-RoBERTa.
The training is done as a sequence labeling task on a newly created parallel Croatian dataset and the model is tested in-vivo as part of our originally developed speech-to-text model for the Croatian language which we will describe in some of our next articles.
Spelling correction consists of two tasks: detecting and correcting spelling mistakes. If a mistake is made the system must first detect the mistake and then try to replace it with its correct form. The automatic spelling correction is very important in many complex NLP systems such as machine translation, speech recognition, text summarization, and search engines. We need these spelling correction systems, so we can build reliable and robust models whose performance will not be badly affected when the data used for building those models contain noise in a form of typos.
The trajectory of building spell correction systems consists of different architectures. Beginning with more traditional approaches such as using dictionary lookup methods and n-gram systems to using advanced deep neural networks such as Recurrent Neural Networks (RNN), Convolutional Neural Networks (CNN) and their various combinations transforming them into sequence-to-sequence models. The latest trend is using a Transformers architecture to build such systems.
Methodology
We have to mention that there is an existing academic spell checker for the Croatian language, Hascheck popularly known as Ispravi.me which is an expert system that learns and upgrades itself every time new unseen words are received. To preserve the purity of the vocabulary they apply supervised learning techniques and human input is needed for the maintenance and improvement of the service. The system uses a corpus of 100 billion word occurrences and a dictionary of 2 million words-variants all confirmed in Croatian texts. Hascheck system is used for creating Croatian n-gram systems which can further be used as a database for building Croatian language technologies.
For the creation of the Croatian typo correction system, we use the Neuspell Toolkit to train the models for accurate correction of spelling mistakes. The Neuspell Toolkit consists of 10 different architectures, each of them improving the results of the previous one. For the purposes of our work, we are using the so-called Subword BERT architecture as the most suitable for our problem. This architecture uses averaged sub-word representation to obtain the word representations which are then fed to a classifier to predict the corrections. Moreover, it uses a pretrained Transformer network, BERT, but can easily implement similar Transformer architectures such as Multilingual BERT, DistilBERT, and XLM-RoBERTa. These pretrained networks are used because of their proven classification accuracy and efficiency, as we are treating this problem as a sequence labeling task where each of the words is labeled with its correct version.
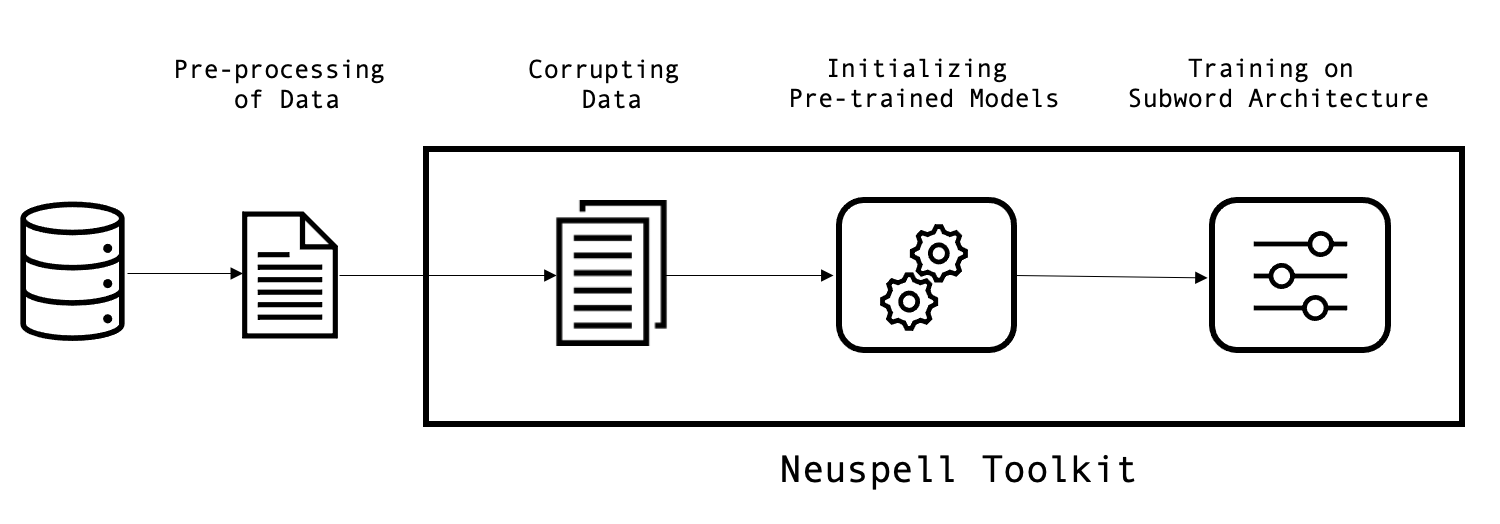
Figure 1: Visual representation of the methodology.
Dataset
Because of the data scarcity and low resources available for the Croatian language, we are using the Croatian Language Dataset (CLD). The dataset consists of about 14.7 million entries gathered from Croatian Wikipedia and the OpenSubtitles project. Due to the size of the dataset, the prepossessing was inevitable. First, we deleted all the duplicates, then we processed only the entries that contained characters from the Croatian alphabet. From the first 10 million sentences, we filtered out all examples that had less than 5 words in them, and that way we obtained a dataset with a size of 6 million entries. For the training and testing phase, we split the dataset 80:10:10 for training, validation, and testing, correspondingly.
Since this dataset only contains the original correct sentences, we needed to generate the corresponding incorrect noisy sentences to create a synthetic parallel dataset. As an addition to the Neuspell toolkit, there are three strategies provided for noising correct sentences. Only the first strategy, the random strategy when modified (taking into consideration the Croatian alphabet) can be used in generating Croatian misspellings. This random strategy incorporates manipulation made with the internal characters of a word in the form of permutation, deletion, insertion, and replacement.
Architecture
Due to the proven efficiency of the BERT model, we tried the Multilingual BERT model as we are working with a non-English dataset. Furthermore, to compare the results, we trained a DistilBERT model on one side as representative of distilled models and the XLM-RoBERTa model on the other side due to its proven significance in multilingual and non-English NLP problems. We experiment with different batch sizes and vocabularies to observe the performances of the models. In the next few sections, we will briefly describe each of the models.
BERT
BERT (Bidirectional Encoder Representations from Transformers) is a language model that is very important in various areas in the field of NLP. The key features that make BERT so empirically powerful are its method for producing bidirectional language representations and its pretraining objectives, Masked Language Modeling (MLM), and Next Sentence Prediction (NSP). The problem of spell correction is considered a sequence labeling downstream task.
The only small difference in the Neuspell implementation in comparison with the original BERT implementation is that the sub-word representations are averaged to obtain the word representations. Thus obtained representations are fed to a classifier that predicts the correct labels, i.e. correct word. Since we are working with the Croatian language, we use the multilingual version of BERT. The fine-tuning of the model over our previously described dataset was made within two epochs with a batch size of 128 and a vocabulary of 200000 words. Everything else remained as in the original paper.
DistilBERT
The DistilBERT model is a compressed version of the original BERT. This smaller model is trained using transfer learning on the same corpus as BERT and uses the same architecture but applies modern linear algebra frameworks to achieve high optimization. To fine-tune this model on our dataset as a spell correction system we just initialized it through Neuspell’s Subword BERT architecture with a batch size of 256 and a vocabulary of 100000 words.
XLM-RoBERTa
The XLM-RoBERTa model is a multilingual model that is pre-trained in 100 different languages. This model follows the XLM approach with changes that are introduced to improve performance at scale. The RoBERTa appendix comes from its training routine same as the original RoBERTa model considering the MLM objective. The model is fine-tuned using the Neuspell implementation using a batch size of 64 and a set of unique words that appear in the training dataset – a vocabulary of 100000 words during 2 epochs.
Evaluation Metrics
The evaluation of the models and their comparison is made using accuracy and word rate correction.
Accuracy − The percentage of correct words of all the words in a sentence.
Word Rate Correction − The percentage of corrected words over the words that need correction. Word rate correction (a.k.a recall) represents how good the model is at correcting only misspelled words.
Accuracy is not always the best metric to measure the performances of the models since it all takes into consideration all matches even if it means correcting words into their correct version. Because the goal is to build models that aim to correct only misspelled words, we incorporate the precision and F1 score metrics to gain a clearer understanding of the outcomes of each of the distinct models.
Results
Here we compare the results from the models. We fine-tuned all the three models on the Croatian parallel dataset to detect and correct misspelled words.
Each of the models is trained on a more corrupted dataset (the syntactically generated noisy sentence contains more misspelled words) and, the models are tested on two different datasets, where one is less corrupted (lower percent of the words in the sentences contain are incorrect), and the other is more corrupted, created in the same way as the training set.
To explain ourselves better, we present the following example of how sentences are noised with the less corrupted and more corrupted strategy. With red color, we mark the words that are syntactically misspelled.
Example: Ivan uči matematiku dok rješava zadatke iz radne bilježnice.
Less corrupted sentence: Ivan uči matmatiku dok resava zadatke iz radne bilježnice.
More corrupted sentence: Ivan uci matemtiku dok resjava zdaatke iz rade bliježnice .
Table 1: Results of the models during the training and testing phase.

In Table I we represent the obtained results during the training and the testing phases. The best scores are obtained with the XLM-RoBERTa model with an accuracy of 94.36% and 93.15% for the less corrupted and the more corrupted dataset respectively.
For all three models, the accuracy of the less corrupted dataset is slightly higher than the accuracy of the more corrupted dataset. This is because the accuracy considers all of the matches, including the right words that remain intact.
As a result, in the testing phase, we also employ the word rate correction metric, i.e., recall, as a true measure of the models’ performances. Once more, XLM-RoBERTa gives the best results when evaluated with the second metric.
Moreover, it can be noticed that word rate correction is slightly lower for the more corrupted dataset. The models give higher scores when evaluated on the less corrupted dataset because when they are evaluated on a more corrupted dataset they strive to correct as many words as possible, and sometimes that means changing incorrect words into new incorrect words. In other words, all models have a higher percentage of falsely converting incorrect words and consequently have a lower word rate correction on the more corrupted dataset. Additionally, the models are evaluated with precision and F1-score to obtain better insight into their performances. Once again, XLM-RoBERTa surpasses the other models.
All of the findings are shown in Figure 2, which illustrates the models’ confusion matrices when tested on both datasets. The rows represent the exact classes of the words (whether they need to be corrected or not), and the columns show the models’ predictions for whether or not they corrected the word. The matrices show that the typo correction models are effective at identifying wrongly typed words and converting them into their correct version, with a percentage of more than 96% for not modifying correct words and more than 72% for repairing typos. The best-performing model is XLM-RoBERTa since it shows better word rate correction and better performance overall evaluation metrics.

Figure 2: Confusion matrices representing the efficiency of the models.
Conclusion
In this article, we went through our paper and briefly described how we re-purposed Neuspell’s Subword BERT architecture to build a spell correction system in the Croatian language. We demonstrated that different Deep Learning implementations can be used for languages other than English with the correct modifications. We intend to increase the accuracy of the current model by including real common Croatian misspelled words in future work, so it can be utilized as a part of a comprehensive speech-to-text system for the Croatian language. In the next few articles, we will describe another Macedonian Typo Correction system and how both of these systems are used as smoothing tools over the outputs of the speech-to-text systems for the corresponding languages.



{kind=link}