
Welcome to the second part of the Typo Correction Models article. Today we will depict the Macedonian Typo Correction Model and how it can be used and implemented in different complex NLP systems.
Introduction
As we discussed in-depth in the previous article: NLP-based Typo Correction Model for Croatian Language, these typo correction models have a huge impact on other NLP systems as they strive to produce clean output that can be further used in other models whose accuracy relies on the cleanness of the input. Once again, we are modifying the Neuspell Toolkit to support the Macedonian language and with that to build important spelling correction systems. This model can be utilized after the Macedonian speech-to-text system to repair possible errors and misspellings.
The Macedonian Typo Correction model is still under development so not every analysis from the Croatian model is included in this article, as it will undergo additional improvements and changes. The Macedonian language is a low-source language which means that there are few available resources online so we can build and train models which focus on solving NLP problems in Macedonian.
To our knowledge, this is the first Macedonian typo correction system that relies on Deep Learning techniques. Previous spell checkers follow the more traditional approaches of dictionary lookup methods and n-gram systems.
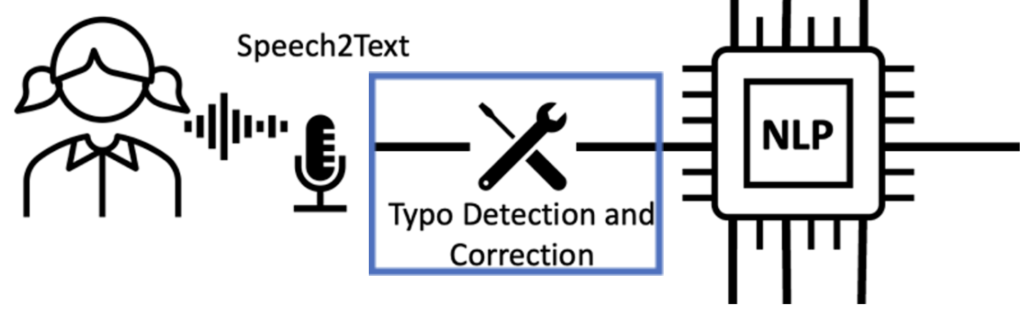
Methodology
In a short recap let’s recall what we learned from the past article. The Neuspell Toolkit is a set of 10 different models where each of them solves the spell correction problems using different architectures and networks. The model of interest is the so-called Subword Bert architecture whose implementation is very similar to Bert’s original implementation, with the only change that they are using averaged sub-word representation to obtain the word representations which are then fed to a classifier to predict the corrections. Because this is a Bert architecture it is very easy to initialize other Bert-like architectures as pretrained networks to train your models on. Given this, we are initializing Bert Multilingual instead of the classical Bert base and/or large, as we work with non-English language, DistilBert to how the small, optimized model will behave in such situations and XLM-Roberta as another proven model in the multilingual problems. Each of these pretrained networks has demonstrated high accuracies and efficiencies in different NLP problems, regardless of the language of interest.
Once again, we are treating the spell correction problem as a sequence labeling task where the goal is to predict the correct label of each word. For that matter, each of the words has to be labeled with its correct version, and to train such models we need a parallel dataset. The dataset will consist of pair of sentences, where the first sentence is the original one, it is written correctly and there are no misspellings in it, and the second one is the noised sentence which contains a few misspelled words. The next subsection will describe which dataset we used and how we adapt it to our problem.
Dataset
Here we are using a Macedonian dataset constructed from Wikipedia articles which consists of about 800 thousand texts. These texts are very long articles so it was decided that each sentence will represent a single example in the new modified dataset. After that, a few preprocessing steps were included such as: removing duplicate examples, cleaning extra characters from the beginning and the end of the sentence, removing extra white spaces, cleaning the examples of links and/or HTML tags, and removing all non-Cyrillic characters. That way we obtained a clean dataset that contained only sentences written in the Macedonian alphabet with a size of around two million examples.
Since we are trying to solve the spell correction problem, we need a parallel corpus with noised sentences that contain misspelled words in them. For that purpose, a modification was made to one of the existing strategies to generate a synthetic dataset from Neuspell. The strategy focuses on random manipulation of the inner characters of chosen words, where permutation, deletion, insertion, and replacement are made over the characters. Each of the sentences is run through the aforementioned system and the generated output is its pair with misspelled words.
Example:
Original sentence: Неговото население непрестајно растело и го надминало бројот на населението на Белград.
Misspelled sentence: Нефовото насление непрестајно рзстело и го надминало бројот на насвелението на Белград.
Figure 1: Visual representation of the methodology.
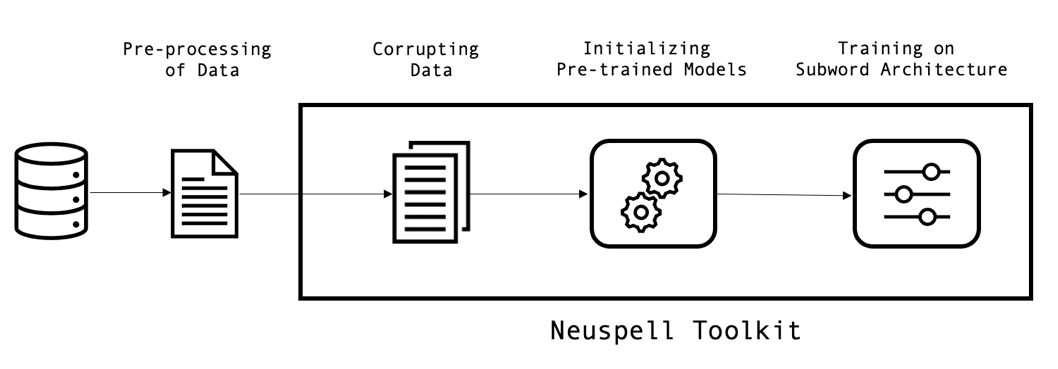
Architecture
In this part, we will just mention the used pretrained Transformer networks as there are already enough resources to introduce yourself to them and we already discussed them in the previous article.
Once again, we are fine-tuning Bert Multilingual, DistilBert, and XLM-Roberta on the newly composed Macedonian dataset.
All three models are fine-tuned over two epochs with a vocabulary of 100000 words and a batch size of 32.
These are only the initial settings, as our work progress, we will experiment with different settings and hyper-parameters to obtain the best results when using the typo correction as a stand-alone system and when using it as a part of a bigger NLP system.
Evaluation Metrics
As evaluation metrics, accuracy and word rate correction are used. With accuracy, we measure the percentage of all matches (a match is considered when each word is matched to its correct version, no matter whether the word of interest was originally correct or misspelled) and with word rate correction we measure the times when an incorrect word is matched and replaced with its correct version.
Results
Since these models are still under development, we will present only the primary results we have acquired so far. Each of the models was trained on the same synthetically generated parallel dataset and evaluated also on the same testing dataset which was previously unknown to the models. The obtained results are presented in Table 1.
Table 1: Results of the models on the Macedonian dataset
| Models | Accuracy | Word Rate Correction |
| DistilBert | 0.963582 | 0.881453 |
| Bert Multilingual | 0.952223 | 0.860259 |
| XLM-Roberta | 0.921319 | 0.738290 |
As we can notice from Table 1, surprisingly the model that gives the best results is DistilBert with an accuracy of around 96% and a word rate correction of 88%. These results are subject to change as the system is still under development. Nevertheless, once again we proved that with small modifications some systems can be re-purposed and trained on different, low-source languages and still give fine results.
Conclusion
With this, we finished the series of articles where we describe our typo correction models. The Croatian Typo Correction model can be used and implemented in various complex NLP systems, and you can read more about it in our paper. Soon the upgraded version of the Macedonian Typo Correction system will be ready to launch and support MAIA, the Macedonian instance of the OpenBrain framework. Moreover, this spell correction system can be used alone and/or as a part of another system similar to how we intend to use it as a smoothing tool to correct misspelled words over the generated outputs of our speech-to-text engines. Stay tuned to see how we will upgrade the Macedonian spell correction model and how we will use it!





{kind=link}