We are moving on with explaining the different intelligent models which comprise the OpenBrain framework. On today’s schedule, we have our text-to-speech deep learning model which is trained on the Macedonian language. We represent MAKEDONKA.
Introduction
Text-to-speech (TTS) is a challenging problem that researchers are trying to solve for the past 30 years. Traditional TTS systems are comprised of two parts: text analysis and speech synthesis. But these traditional systems encounter several problems that derive from the one-layer nonlinear transformation units, such as Hidden Markov models, maximum Entropy-based methods, and concatenation base synthesis method. The existing attempts to create Macedonian TTS rely on concatenation-based synthesis methods which are limited by the pitch period or starting point and the maintenance of smooth transitions. For overcoming these problems, the first Macedonian TTS system follows a parametric speech synthesis based on a Deep Learning approach. The new strategy consists of three phases: text analysis, parameters prediction, and speech synthesis, each of them relying on an appropriate deep neural network (DNN). This approach obtains more natural generated speech because it directly maps the linguistic features into acoustic features. With the publishing of this paper, not only the first Macedonian TTS system is released, but also the first high-quality speech dataset for the Macedonian language which can be used in training and improving other TTS systems and a complete overview of various TTS models implementations, their characteristics, and differences.
Methods and Methodology
In this section, we are describing how the novel high-quality speech dataset was constructed and why is it important, how its preprocessing was conducted, and we are explaining the existing architecture of MAKEDONKA [1].
Dataset Creation
For every intelligent system creation having an appropriate and suitable dataset is essential. However, not often when creating state-of-the-art models or working with low-resource languages those datasets are already available, so a need arises for creating proper datasets from scratch. The dataset used for training MAKEDONKA is developed following the guidelines of the LJ Speech Dataset [2] which is considered to be a golden standard for testing the accuracy of DNN-based synthesizers for English languages. The dataset was produced by a female speaker using a professional microphone to eliminate the majority of background noise. A software tool was created to automatically serve the speaker with the consecutive samples from the text corpus and enables on-click creation of audio files in order to facilitate the recording process. The interface of the software is presented in Figure 1.
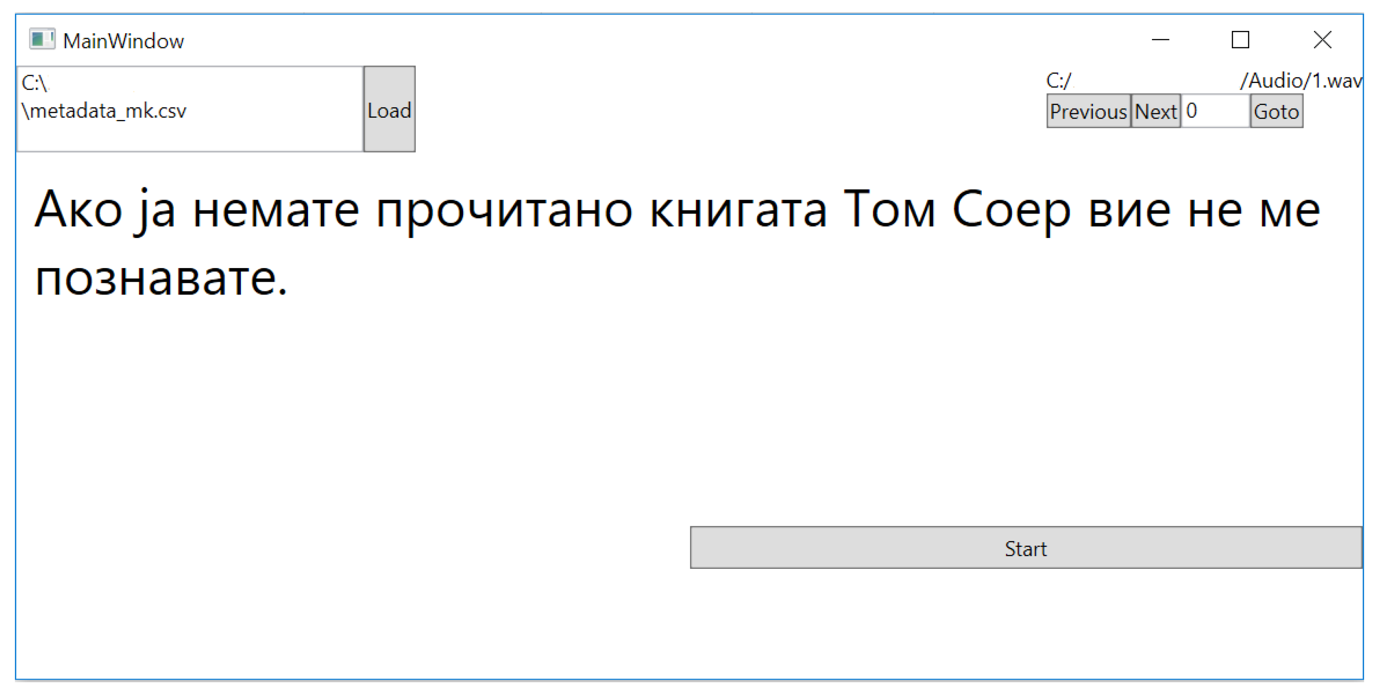
Figure 1: Software module for dataset creation. The displayed sentence is the Macedonian translation of the first sentences in Huckleberry Finn.
As an input, the speaker needs to provide a .csv file that contains the whole text corpus. Subsequently, the software automatically reads line by line and the speaker generates .wav files by clicking on the “start” button. To be more user-friendly as soon as the recording process starts, the button becomes red, and is labeled as “stop”. One more click on the button, or just click the “enter” key from the keyboard, and the audio file is saved in .wav format. Consequently, a new portion of the sample is displayed to be read. At the top right corner, the speaker is able to manually switch among the text samples if there is a need to record some samples all over again.
For the purposes of this system, the text corpus was created by reading the Macedonian translation of Mark Twain’s “Huckleberry Finn”, which produced 15 hours of recorded material that corresponded to a total of 7686 recorded .wav files. Moreover, the corpus was extended to 10,433 records by carefully choosing specific sentences that cover a range of complex words and dividing them into subsentences.
Preprocessing
The data preprocessing was made in two steps. Because the dataset consists of two types of files, two different preprocessing methods were put into use.
The editing of the text files is composed of replacing the abbreviations with their appropriate original meaning, removing the typo errors, and replacing the numeric values with their textual representations. As in the training phase, these alterations of the text files were applied also in the inference text.
On the other hand, the audio files also require additional preprocessing to facilitate the alignment between audio files and texts. Here, each audio file is trimmed i.e the silence at the beginning and the end is removed, as well as any other noise that may appear. To obtain an optimized training phase, long sentences were split into more subsentences allowing the recorded files to have a duration no longer than 10 seconds.
Deep Learning Approach
It was experimented with many different architectures and models, but Deep Voice 3 was chosen as the most appropriate model for the creation of the Macedonian TTS system since it outperforms other models.
This model can synthesize more than 10M sentences per day and its sound-to-phoneme mapping ability is the most suitable for the Macedonian language, which is consistent and phonemic in practice, and it follows the principle of one grapheme per phoneme. This one-to-one correspondence is described by the principle, “write as you speak and read as it is written” [3].
Deep Voice 3 is a fully convolutional architecture for speech synthesis. Its character-to-spectrogram architecture enables fully parallel computation, and the training is much faster than in the RNN architectures. The architecture generates monotonic attention behavior, which avoids error modes that are common in sequence-to-sequence models.
This architecture also converts the characters, phonemes, stresses, and other textual features into a variety of vocoder parameters that are used as inputs into audio waveform synthesis models. When mentioning vocoder parameters, we talk about mel-band spectrograms, linear-scale log magnitude spectrograms, fundamental frequency, spectral envelope, and aperiodicity parameters.
The Deep Voice 3 architecture mainly consists of an encoder, decoder, and converter layer. The encoder layer transforms the previously defined textual features into internally learned feature representations. Those features are in a (key, value) form and they are fed into the attention-based decoder. The decoder uses its convolutional attention mechanism to transform those features into low-dimensional audio representation, i.e., Mel-scale log magnitude spectrograms that correspond to the output audio. The hidden layers of the decoder are fed into the third converter layer, which can predict the acoustic features for waveform synthesis. Figure 2 presents the detailed architecture of the model and the methodology workflow.
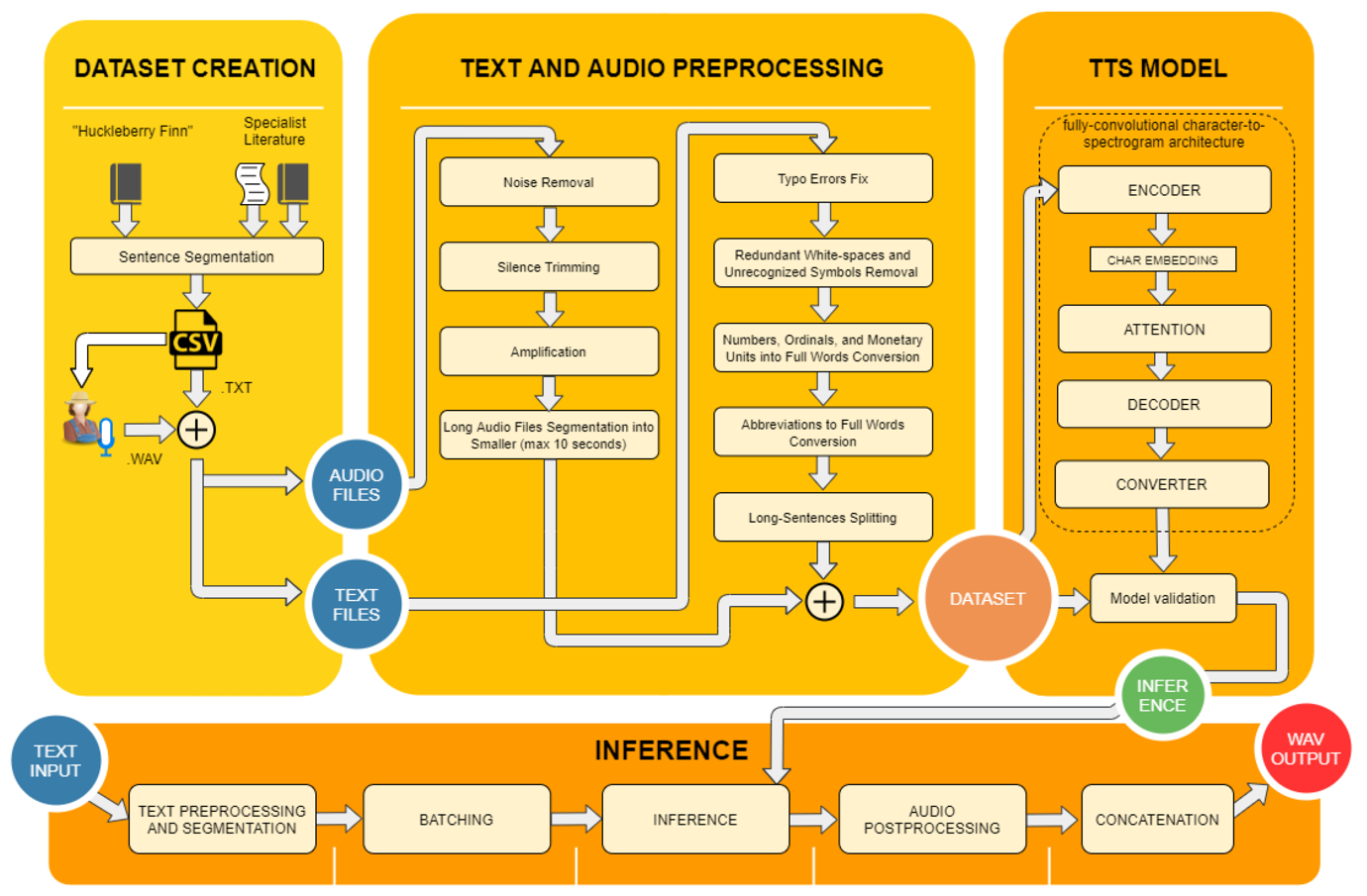
Figure 2: MAKEDONKA’s text-to-speech methodology.
Figure 2 represents the whole workflow which is depicted via four separate stages. The first is the Dataset creation as well as the production of files in a suitable format that is recognized by the TTS model. The following stage is corpus preprocessing as mentioned in the previous section.
As soon as the dataset is ready, it is run through the TTS model. The training of the model is followed by validation, which means that each 10 K steps are evaluated before the training process proceeds. The evaluation is done on external, unknown sentences that provide insight into the advancement of the learned dependencies between the dataset and the hidden layer weights. Finally, the Inference stage is shown. This stage itself is independent from the previous one and it uses the leverage of the already created checkpoints. New input texts are preprocessed as in the text and audio preprocessing stage and are additionally segmented. This segmentation is done in order to prevent inferences with a duration of over 10 s. As the input sentences are segmented, they are batched to preserve the order. Each of them is predicted by the checkpoint upon which an intelligible speech is synthesized. The segments are put together during the audio postprocessing and concatenation step, and they are presented as a single .wav file.
Results
The audio dataset was recorded at a sample rate of 22.5 kHz, and it consists of approximately 20 hours of Macedonian high-quality single-speaker speech. The training was performed by using NVIDIA Tesla P100 with 16GB RAM. The total training time by using a batch size of 16 took 21 days and 16 h. The training was completed after 620 K steps, but from Figure 3 it can be noticed that the model started to produce an intelligible, understandable, and partially human-like speech after 50 K steps. Hereafter, the model started to improve itself by losing the “robotic” component in the synthesized speech and achieved completely human-like speech until the end of the training.

Figure 3: Attention changing during the training process
At each checkpoint, the model was evaluated on seven different sentences that cover special cases in the Macedonian language, such as long words; compound words; commas somewhere in the sentence; sentences ending with a full stop, question marks, and exclamation marks to check whether the model is able to change the intonation in the synthesized speech; and, tongue twisters, words with multiple adjacent consonants, such as the word “Shtrk”. The audio files from the synthesized speech across the checkpoints are available on GitHub https://f-data.github.io/TTS/.
Figure 4 presents the metrics that speak of the performance of the training models. The loss function is a metric that refers to the accuracy of the prediction and the main objective is to minimize the model errors or minimize the loss function. As seen from the figure, the loss functions behave in a desired manner, it gradually decreases, converging to a value of 0.1731 after 162.2 K steps in four days and 11 h of training.

Figure 4: Tensorboard scalars of the learning methods.
Learning rate plays a vital role in minimizing the loss function i.e. it dictates the speed at which we want our model to learn. The initial learning rate was set to 0.0005 and after four days and 5 h of training, or 151.2 K steps, it decreases to a value of 0.000081335. Furthermore, the gradient norm that is presented calculates the L2 norm of the gradients of the last layer of the Deep learning network. If its value is too small, it might indicate a vanishing gradient that affects the upper layers of the Deep learning network, making it hard for the network to learn and tune the parameters. On the contrary, if its value is too high, it may indicate exploding a gradient phenomenon where the model is unstable and does not learn from the data. The last performance metric refers to the ability of the model to predict the mel-spectrograms. The L1 norm of the metric is decreasing across the iteration steps, reaching 0.03304 after 172.8 K steps, or four days and 18 h of training. The model and the samples can be found on GitHub https://github.com/f-data/TTS-Makedonka.
The quality of the model has been assessed based on reliable and valid listening tests to assess overall TTS model performance—the Mean Opinion Score (MOS) [4, 5].
Table 1 presents the obtained MOS values for the ground truth and the selected TTS model, which are 4.6234±0.2739 and 3.9285±0.1210, correspondingly. Fifteen distinct listeners performed the assessment on 40 original (ground truth) and 40 synthesized audio files. The MOS measure indicates good quality audio, with no additional effort to understand the words, distinguishable sounds, no annoying pronunciation, preferred speed, and pleasant voice.
Table 1: Mean Opinion Score (MOS) Results.
| Experiment | Subjective Five-Scale MOS |
| Ground Truth | 4.6234 ± 0.2739 |
| Deep Voice 3 | 3.9285 ± 0.1210 |
Conclusion
Today we presented MAKEDONKA, a successful effort to train a human-like TTS model for the Macedonian language. The model is the first of its kind and it is available to be used as a module in any kind of software that needs this type of service. As such, MAKEDONKA, the Macedonian TTS system is one of the intelligent units that are part of the MAIA, the Macedonian instance of the OpenBrain framework. The methodology presented in the paper relies on a previously confirmed Deep learning-based methodology—Deep Voice 3. Moreover, for the dataset creation, an additional software tool was built for new records management, and it was created approximately 20 hours-long training corpora from scratch. The model has been improved in the later steps, and the robotic-like components in the synthesized speech have been almost removed after 200 K steps of training. The quality of the generated audio files has been assessed while using the MOS metric, which is commonly used to assess the TTS systems.
The original paper can be found on: https://www.mdpi.com/2076-3417/10/19/6882. The training dataset, the synthesized samples at different checkpoints, the source code, and the trained model are publicly available for further improvement on GitHub https://github.com/f-data/TTS-Makedonka.





{kind=link}